Extend Independent and Controllable Assurance Capabilities to the Cloud
Integrated business performance management across physical, virtual and cloud environments, makes business O&M stable and worry-free.
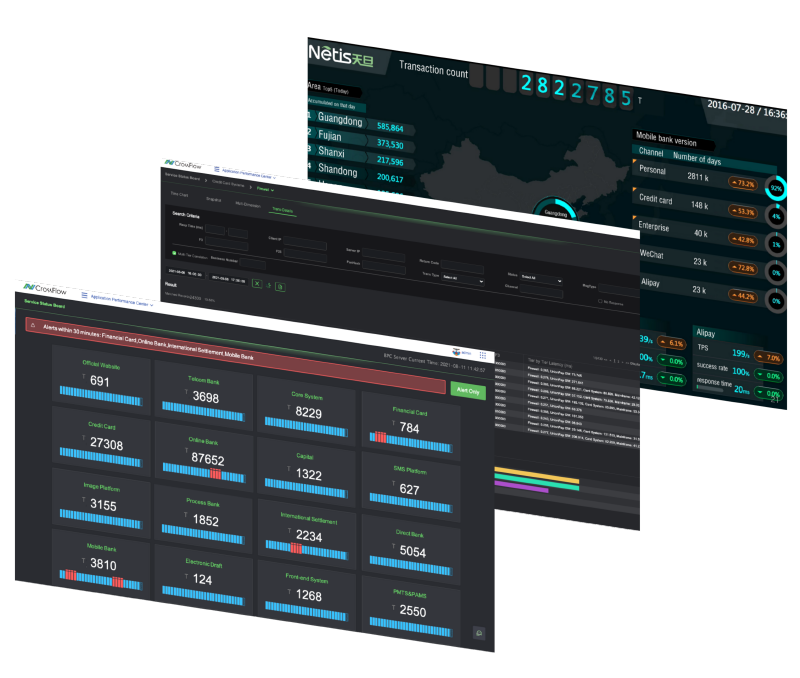
Business Performance Management
Unified management and comprehensive analysis over hybrid IT architecture improve business continuity.
Network Performance Management
Service-oriented network performance management and unified perspective with business strategy make network value visible!

Wire-data, Unify Big-data Language and Wire Data Boundaries
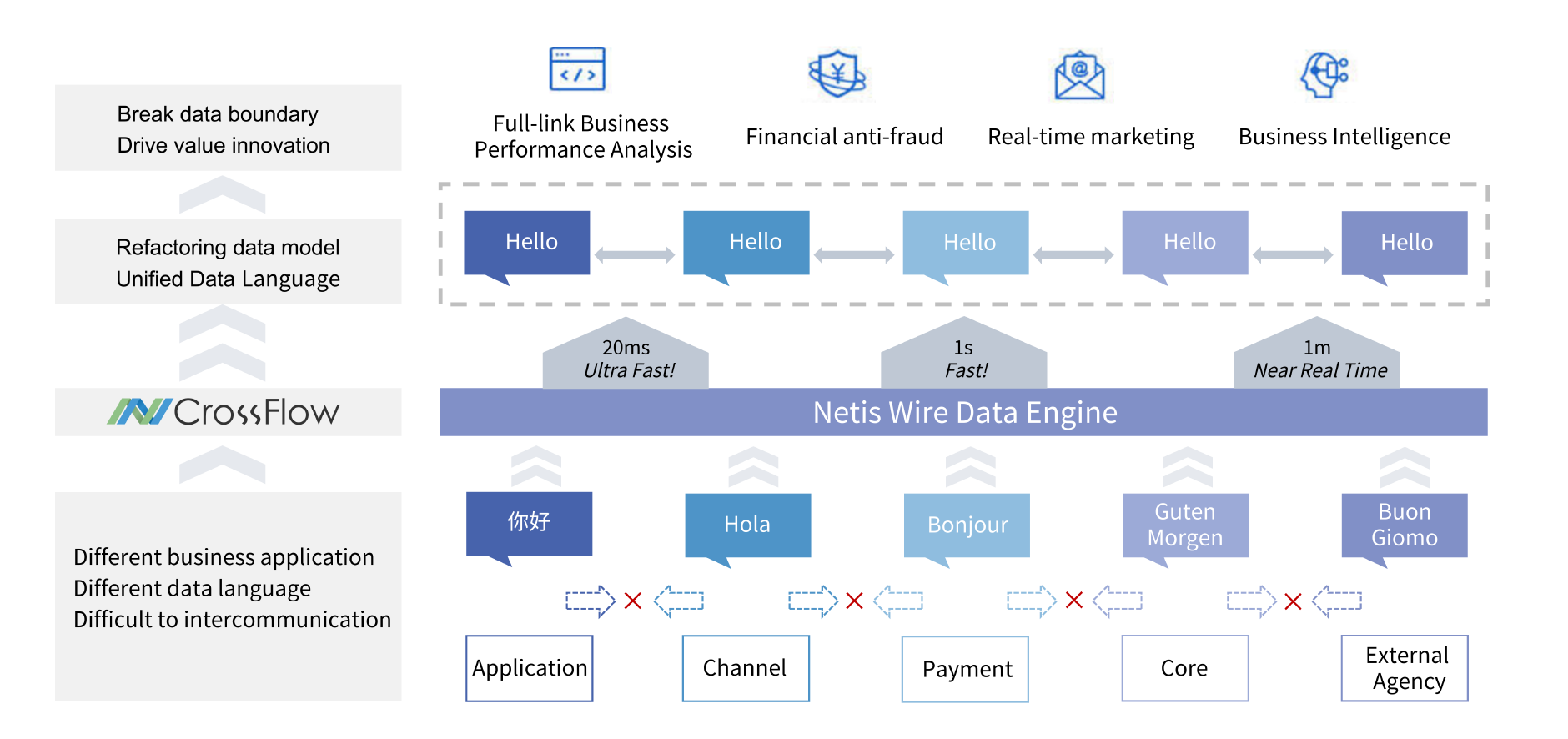
Solutions
Banking
Securities
Insurance
Gartner Certified Technology Trend Upgrade
Netis’ products use real network data to provide multitier correlation capabilities. This enables Netis’ products to perform service-oriented analysis for troubleshooting and key performance indicators(KPI) reporting purposes.
—— 《Cool Vendor in Performance Analysis, 2017》
2019-2021, Netis was listed in Gartner’s latest AI report “Competitive Landscape: AI Startups in China”
2017-2020, Netis is listed in the “Honorable Mentions” of two research reports of 2017 NPMD Magic Quadrant and NPMD Critical Capabilities.
2017 Netis was listed as the world’s cool vendor in Gartner performance analysis in 2017, and became the only one Chinese company selected.
2016, Netis was selected in three heavyweight reports such as Gartner Hyper Cycle and IT Market Clock, respectively listed as “Selected Suppliers” and “Sample Suppliers”














































Online Message
Contact Netis sales representative immediately to learn more about Netis products performance and how to improve your business.